Predicting and Preventing Customer Churn using Modelbit and Hightouch
Learn how you can predict churn scores in Snowflake with Modelbit and sync them to tools like Salesforce using Hightouch.
Made by: Modelbit
|7 minutes



With modern data science and machine learning, it’s easier than ever to predict whether a customer is going to churn. With the right training data and modeling libraries, we can quickly train a model that scores a customer’s likelihood of churning.
Getting this information into the hands of our teammates who can save the account is the most critical piece of the puzzle.
In this playbook, you’ll learn how to create a model that predicts the likelihood that a customer will churn. Then you’ll use Modelbit to deploy that model to Snowflake, where it will run those predictions on every customer, every single day. Finally, you’ll use Hightouch to sync those predictions to Salesforce (and other tools), so that every Customer Success Manager can easily see the health of each of their accounts, and take appropriate action.
- You’re a data scientist, or you have a data team who can create predictive models.
- You have customer data to train your model
- You have a data warehouse where you’ll store your predictions (This scenario uses Snowflake, but this approach works for any data warehouse.)
- You have a Hightouch account
- You have a Salesforce account or another CRM tool where you want to access your predictions. (Hightouch supports over 200 end destinations, including Salesforce.)
You can begin by training a model to predict customer churn. If you already have your own models, skip to Step 2, where you’ll deploy your model to Snowflake.
-
We’ll start by getting a DataFrame of our accounts. This particular example uses a sample from Modelbit. In reality, this dataset will come from anywhere you store your customer data.
This dataset includes client firmographic information (like industry and number of employees) as well as behavioral data (like the percent of the last thirty days they were active in the product, and the number of days late they were late in paying their bill). Finally, of course, we know whether the customer churned or not.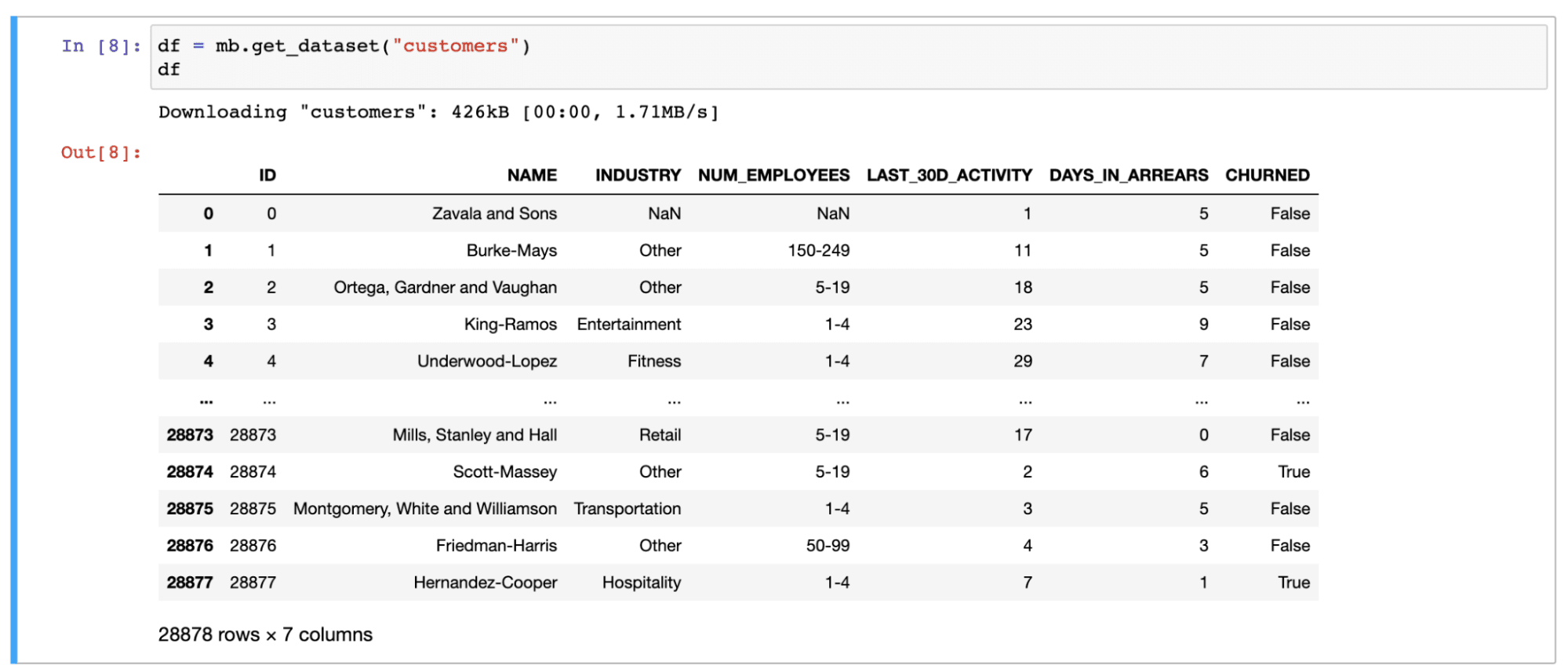
-
Next, you need to build a predictive model from your data. To build a model based on your sample data, you can use an XGBoost classifier with a OneHot encoder. The model specifics varies based on what makes the most sense for your data.
import pandas as pd from sklearn.pipeline import Pipeline from sklearn.preprocessing import OneHotEncoder from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score from xgboost import XGBClassifier pipeline = Pipeline([ ('encoder', OneHotEncoder(handle_unknown = 'ignore')), ('classifier', XGBClassifier()) ]) X_train, X_test, y_train, y_test = train_test_split(X, y) pipeline.fit(X_train, y_train) y_pred = pipeline.predict(X_test) accuracy_score(y_test, y_pred) -
Finally, you need to evaluate your model’s accuracy and iterate. The last line of code in this block outputs the model’s accuracy score, which is the number of classifications it got correct in testing. How high a score works for you will be a decision you’ll want to make in partnership with business stakeholders. If you decide you need to improve your score, it’s worth seeing what other data you may have, including them out as features in the model, and trying other model methods
For this particular example data the accuracy score was 0.87, which means you’re more than ready to deploy the model.
Modelbit is a platform that allows you to deploy machine learning models directly to Snowflake and other cloud environments. It’s useful in situations like this one, where you want to take a machine-learning model and run it directly in our warehouse.
-
You can head to www.modelbit.com to learn more, and click the “Start Your Free Trial” button to create an account.
-
If you’re new to Modelbit, you’ll see this new user onboarding guide which you should complete before returning to this playbook.
Now that you have your Customer Churn Predictor as well as your Modelbit account, you can deploy your model.
-
Start by installing the Modelbit Python package from the command line:
pip install modelbit -
Now, from the same Notebook where you build the Customer Churn Prediction model, login to Modelbit:
import modelbit mb = modelbit.login() -
Finally, you can write a Python function that gives you an inference, and deploy it to Modelbit:
def customer_churn_likelihood(industry: str, num_employees: str, last_30d_activity: int, days_in_arrears: int) -> float: return pipeline.predict_proba( [[industry, num_employees, last_30d_activity, days_in_arrears]] )[0] mb.deploy(customer_churn_likelihood) -
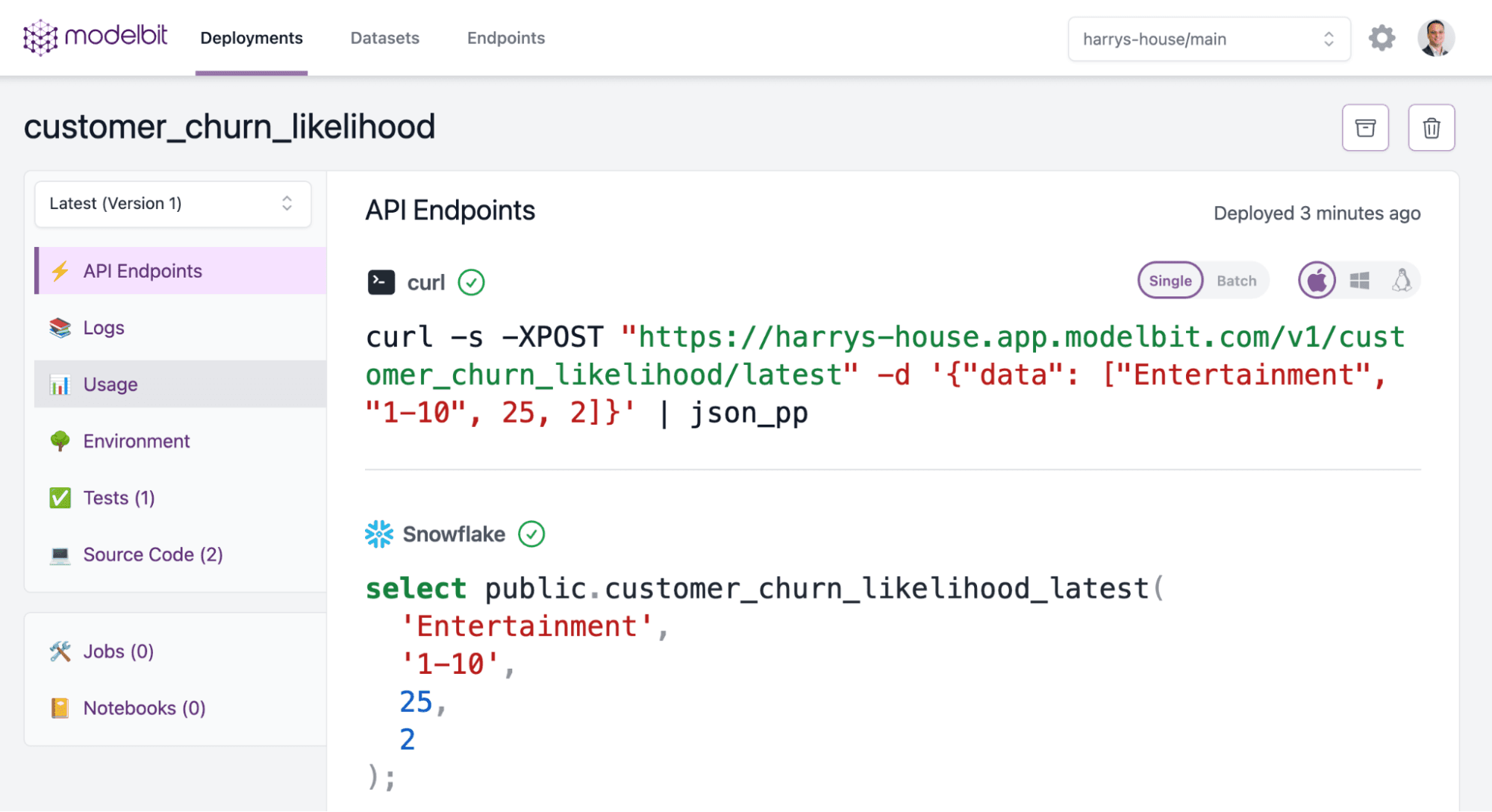
Once you run that, Modelbit shows you the endpoints where you can call your model from, including the SQL function that you can use to get your churn likelihood predictions. Here is an example of what you’ll see in Modelbit:
-
By running this query, you can get the churn score for any customer, right here in the database:
select public.customer_churn_likelihood_latest(industry, num_employees, last_30d_activity, days_in_arrears); -
If you want to update the churn scores for every single customer, just run:
update customers set churn_likelihood = public.customer_churn_likelihood_latest(industry, num_employees, last_30d_activity, days_in_arrears);
You can run that SQL every day on a schedule, or even drop it into a dbt model to get churn scores as often as you want.
Now that your churn scores are in Snowflake, you can use Hightouch to sync those scores to Salesforce.
- Select from our supported source types and click Continue.
- Enter your source configuration details and then click Continue.
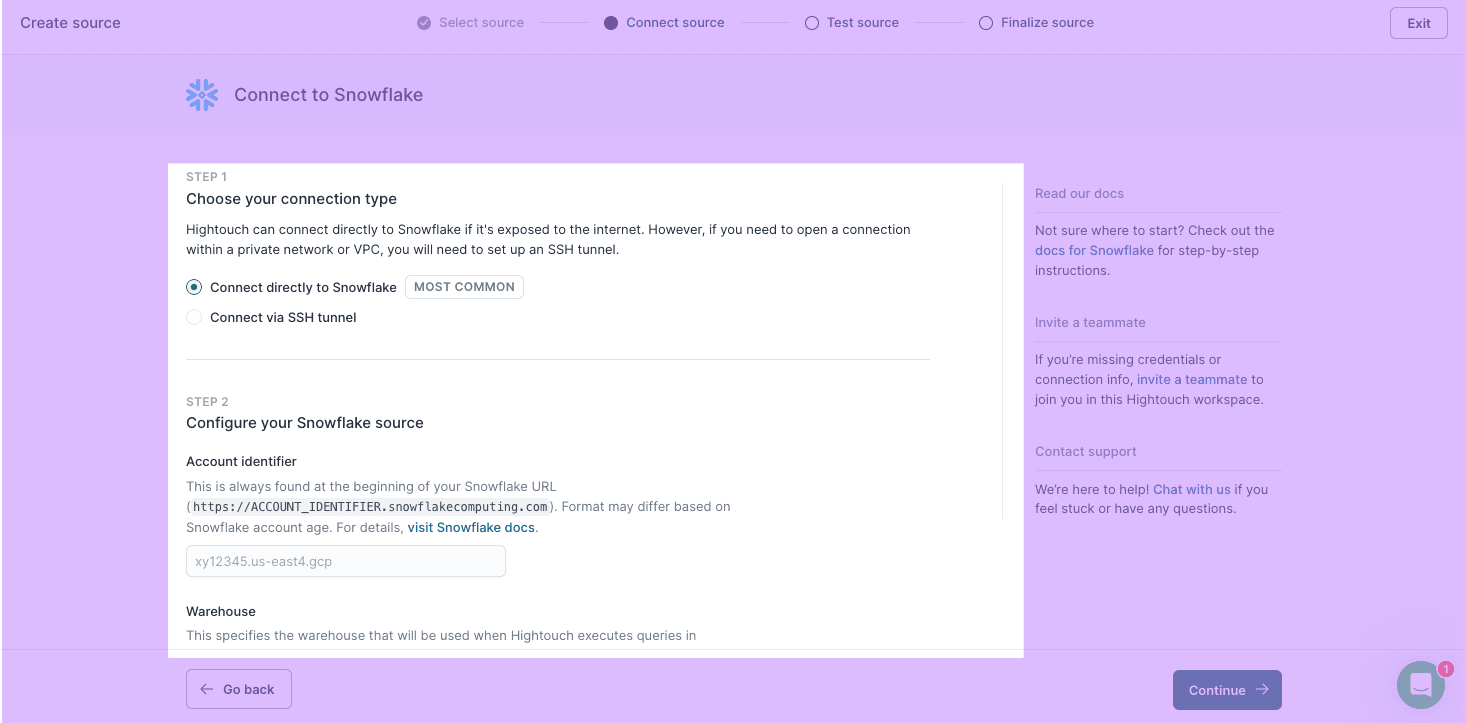
- Name your source and click Finish.
-
Navigate to Models in Hightouch and click Add model.
-
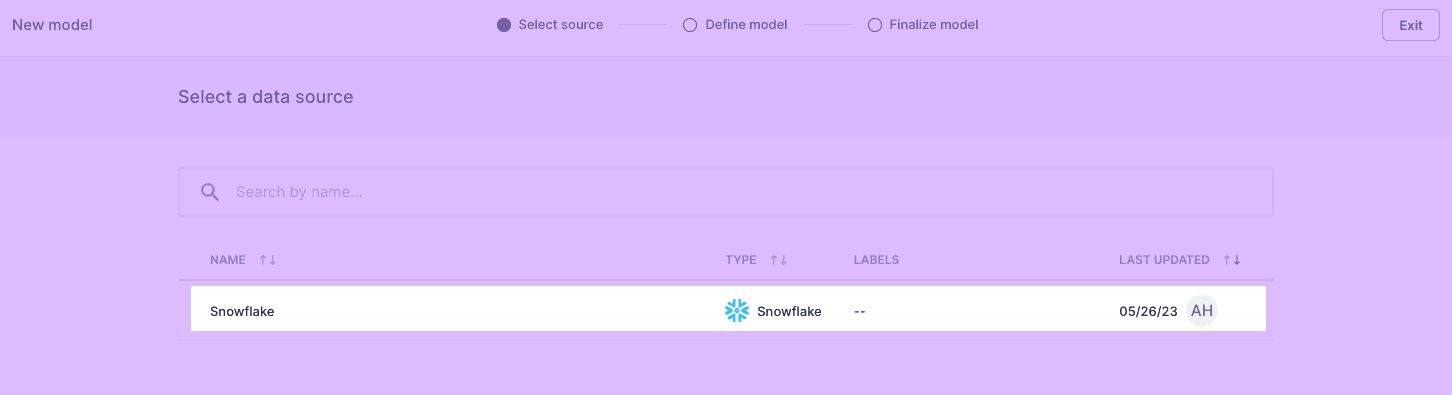
Select the data source you connected earlier and click Continue.
-
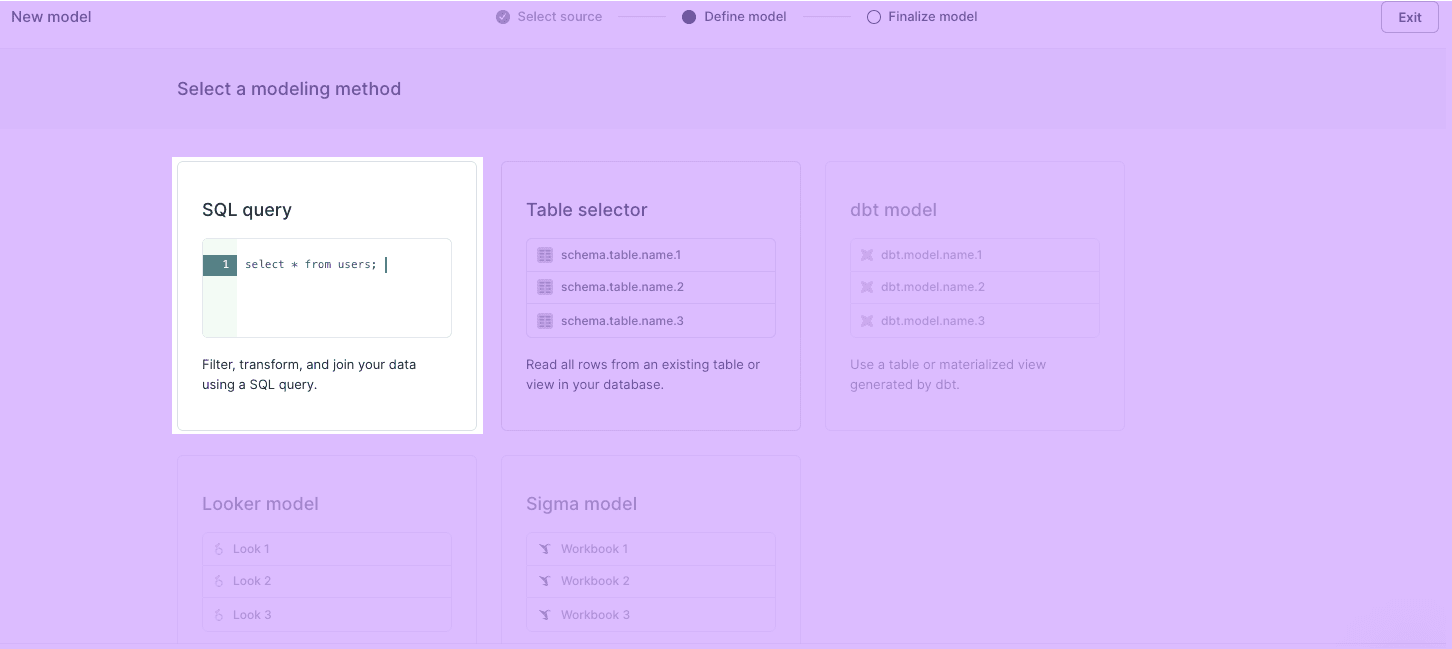
Next, you want to define your data model. You can define your data using either a SQL editor, table selector, your existing dbt models, or even your Looks if you use Looker as your BI tool. (NOTE: this scenario uses the SQL editor.)
-
Input a query that selects your churn scores.
Select customer_id, churn_likelihood FROM PUBLIC.Customers -
Preview your results for accuracy, and add details like a Name for the model before clicking Finish.
- Navigate to destinations and click Add Destination. Select Salesforce and click Continue.
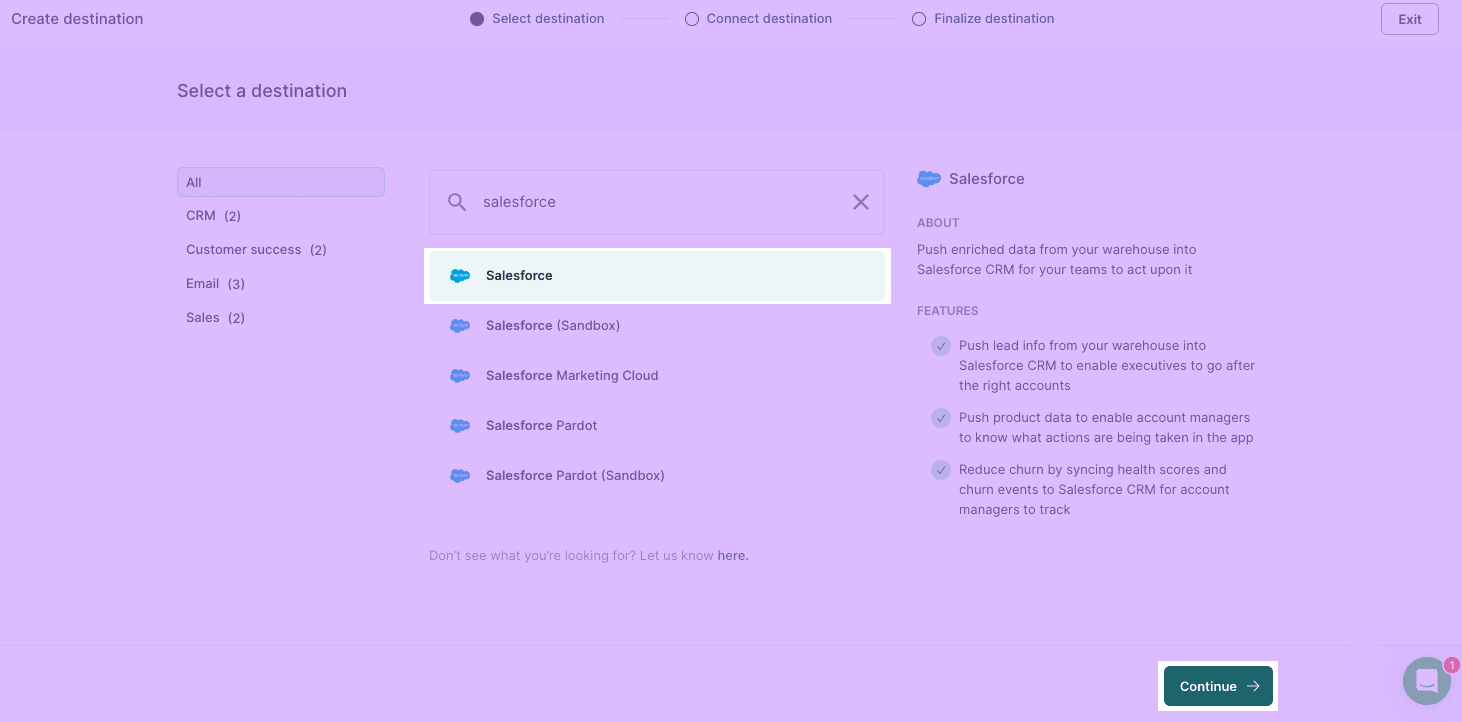
- Connect to Salesforce with OAuth to open up a new window to input your credentials. Once done, click Continue.
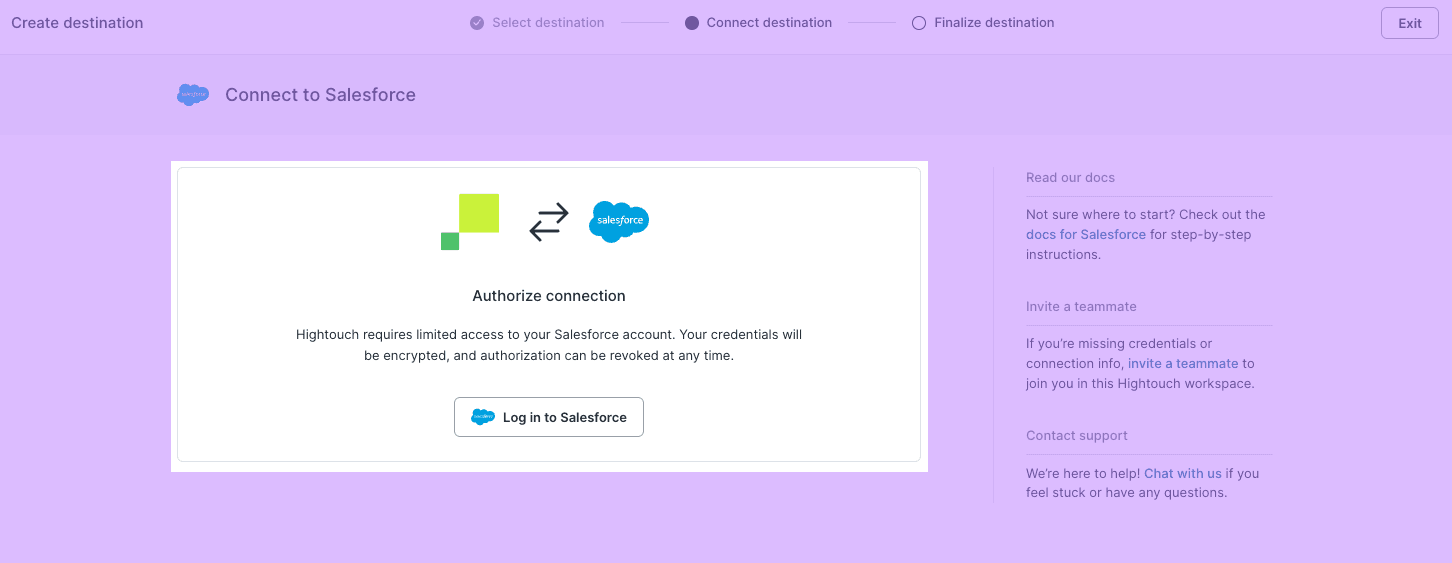
- Name the destination and click Finish.
-
Select Syncs, click Add a sync, select your Salesforce destination, and click Continue.
-
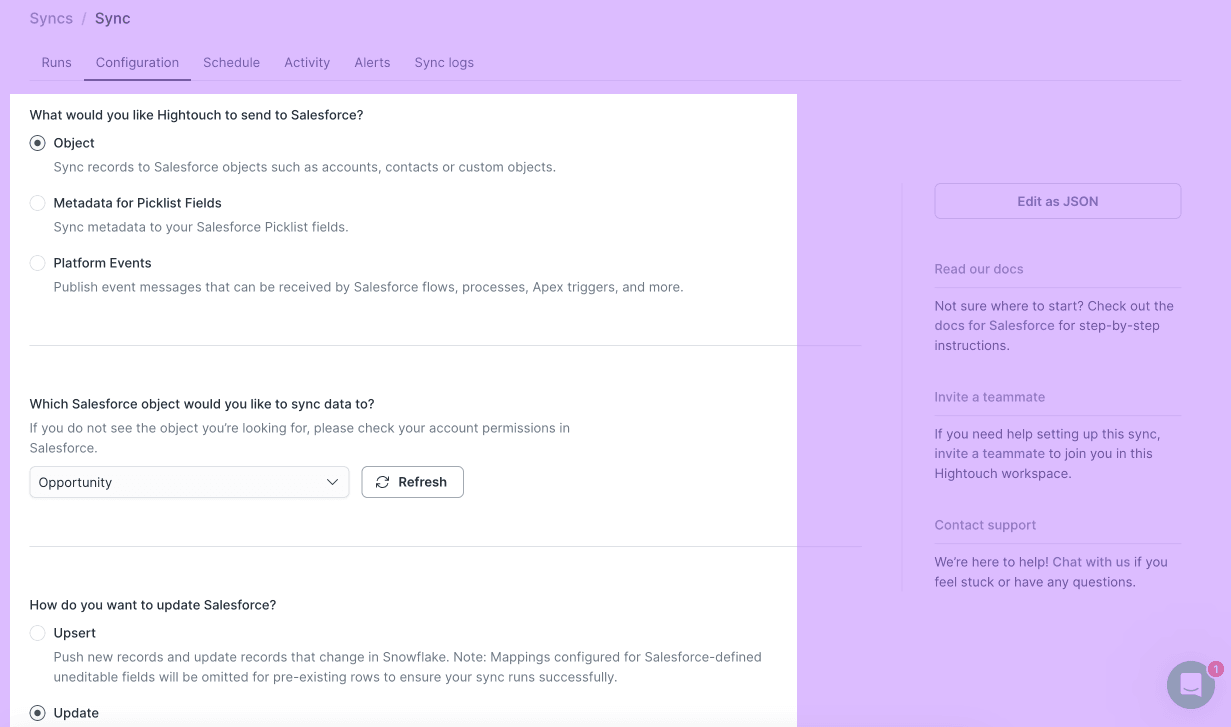
Next, configure your settings and choose how you want your data synced to Salesforce. You'll also need to choose an object and define how your records should be updated in Salesforce. After this, you simply need to select a primary key and choose which columns you want to sync to Salesforce. You may need to make a new value in Salesforce to map your churn score to, if you do not have one already.
-
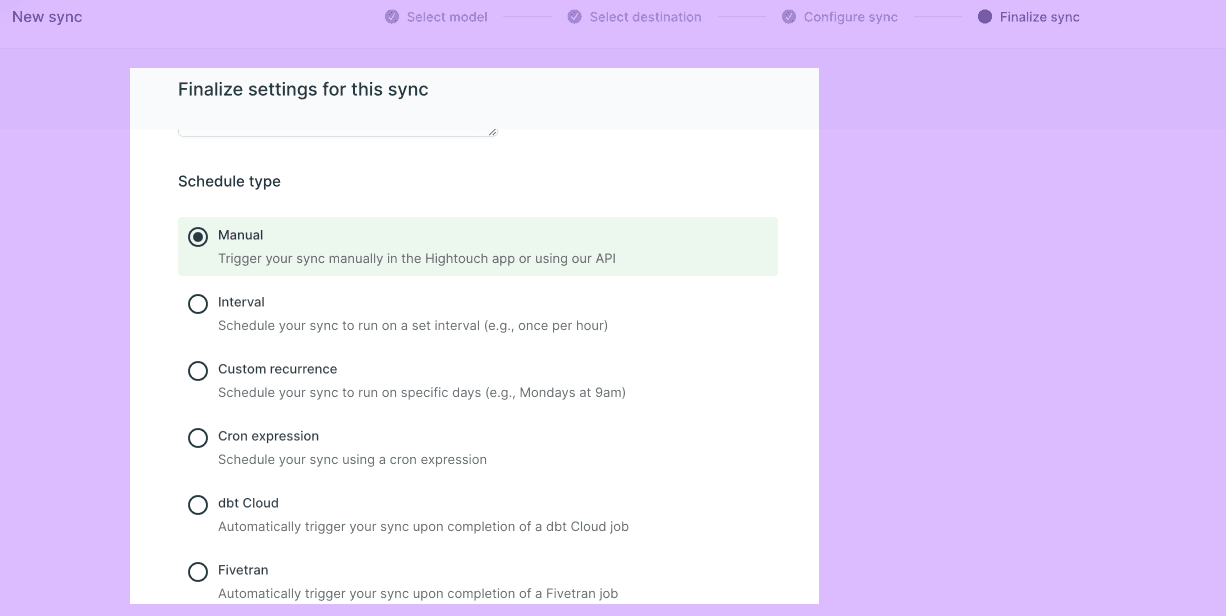
After you've mapped your columns, you can set your sync schedule. For now, make this a daily sync by selecting “interval” and setting this up to sync once a day.
-
With your sync configured, simply click Run, and your churn score data begins syncing to Salesforce.
With your churn score prediction snow populated in Salesforce your Customer Success Manager can take action before your customers churn.
Now that your sync is running, your customer success team can know which customers have a high likelihood of churning daily, and work to save those customers and grow your business. You can take this same approach utilizing Modelbit, Snowflake, and Hightouch to implement other predictive models and activate those predictions to downstream tools.