A practical guide to using the new Hightouch Fivetran extension
How we automated a near real-time end-to-end pipeline in 15 minutes, without an orchestrator
Alexis Jones
January 4, 2023
|7 minutes

Hightouch and Fivetran recently announced a new extension to automatically initiate Hightouch syncs from Fivetran when fresh data is available. While this might seem simple, it marks a significant milestone for the modern data stack.
The last thing data engineers want (or need) is to unnecessarily onboard yet another tool into their stack. So when existing tools have built-in scheduling functionality…it’s compelling to adopt it. But there’s an issue. Each of these tools works independently, making it difficult to ensure seamless interoperability. Hence, orchestrators.
In a perfect world, all the tools would seamlessly work together to make it easy for data engineers to create these cross-tool dependencies in their data jobs.
Well…data engineers rejoice, because with this new integration, you have an automated, cohesive way to:
- Ensure Fivetran syncs are complete before running dbt transformations.
- Run a Hightouch sync only after both Fivetran and dbt have completed successfully.
tl;dr: Practitioners can build and automate end-to-end data activation pipelines—with multiple sources, destinations, and tools in between—without needing to rely on a complicated orchestration tool 👏.
Our Proof of Concept & Requirements
Our own data team was really excited to try it out, and this post gives a practical walk-through of the steps they took to solve a common use case: enriching Salesforce data from our Postgres database.
Their goals were to evaluate whether 1) the new extension met all the job dependency requirements and 2) it was easy to configure.
We’re happy to report that in this proof of concept, our data team was able to configure an entire working pipeline within 15 minutes, from which point it only took a few seconds to run the syncs and transformation.
Making (Near) Real-Time a Reality
In the process, the team experienced a significant “aha” moment:
Data engineers tend to ascribe to the idea that the data warehouse supports only batch processing. This is for good reason: transformation jobs typically only run a few times a day and can take several hours to complete, making real-time in the warehouse a pipedream.
But what about supporting targeted use cases that demand more “real-time” data? In these scenarios, engineers can use this extension to very quickly stand up a parallel data pipeline, without needing to understand the underlying (often complicated) data architecture. That data can flow through the pipeline as regularly as your ELT (and Reverse ELT) pipelines will allow…as frequently as every five minutes with Fivetran.
In our proof of concept, the team configured a sidecar ELT pipeline to run a small portion of the daily batch update between both Postgres and Salesforce to Snowflake to solve a customer success use case. They built a specific dbt model (Salesforce_accounts) to hydrate Salesforce with the freshest customer data and were able to refresh that model every 15 minutes without impacting (or worrying about) the current data infrastructure.
Let’s step through the details.
A Simple Proof of Concept Scenario
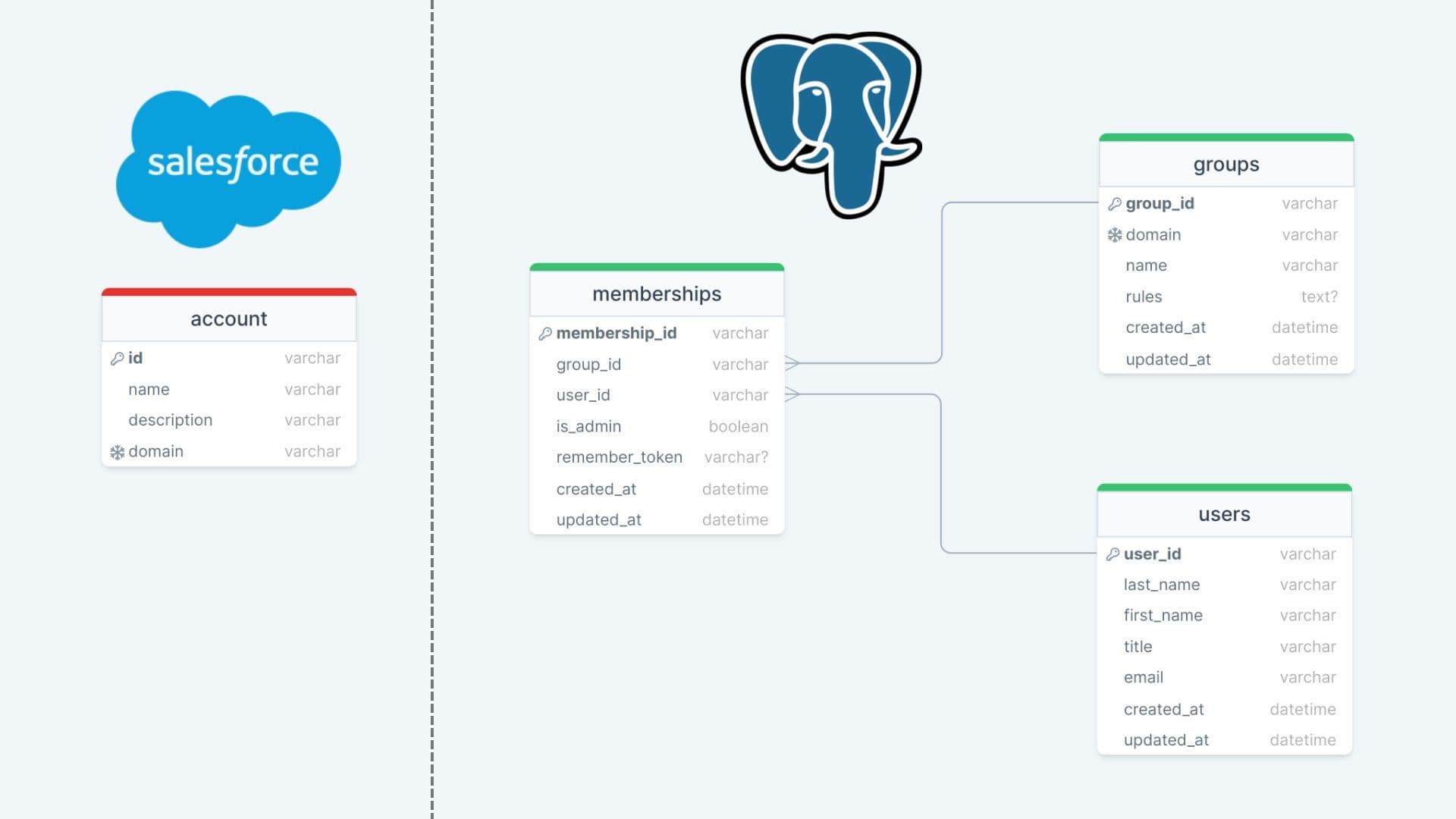
Bringing Salesforce and Postgres data together to create a real-time customer snapshot
In this scenario, the team referenced a Postgres database where our website stores membership in domain groups. On the business side, our customer success team uses Salesforce to handle incoming support calls, and they want to prioritize requests for clients with more than 15 active users.
Since clients can add and remove users in a self-service manner in-app, the active user count that the success team references won’t be accurate unless that data is frequently synced.
To maintain the most up-to-date user count in Salesforce, our data team set up a pipeline to sync source data to the warehouse and calculate the number of active users per account.
They then used Hightouch to sync the enriched data back to Salesforce, updating this critical metric available for the customer success team every 15 minutes. Below is a walkthrough of the steps involved.
Step One: Schedule Fivetran Syncs from our Data Sources
The first step was to link Fivetran to our GitHub organization.
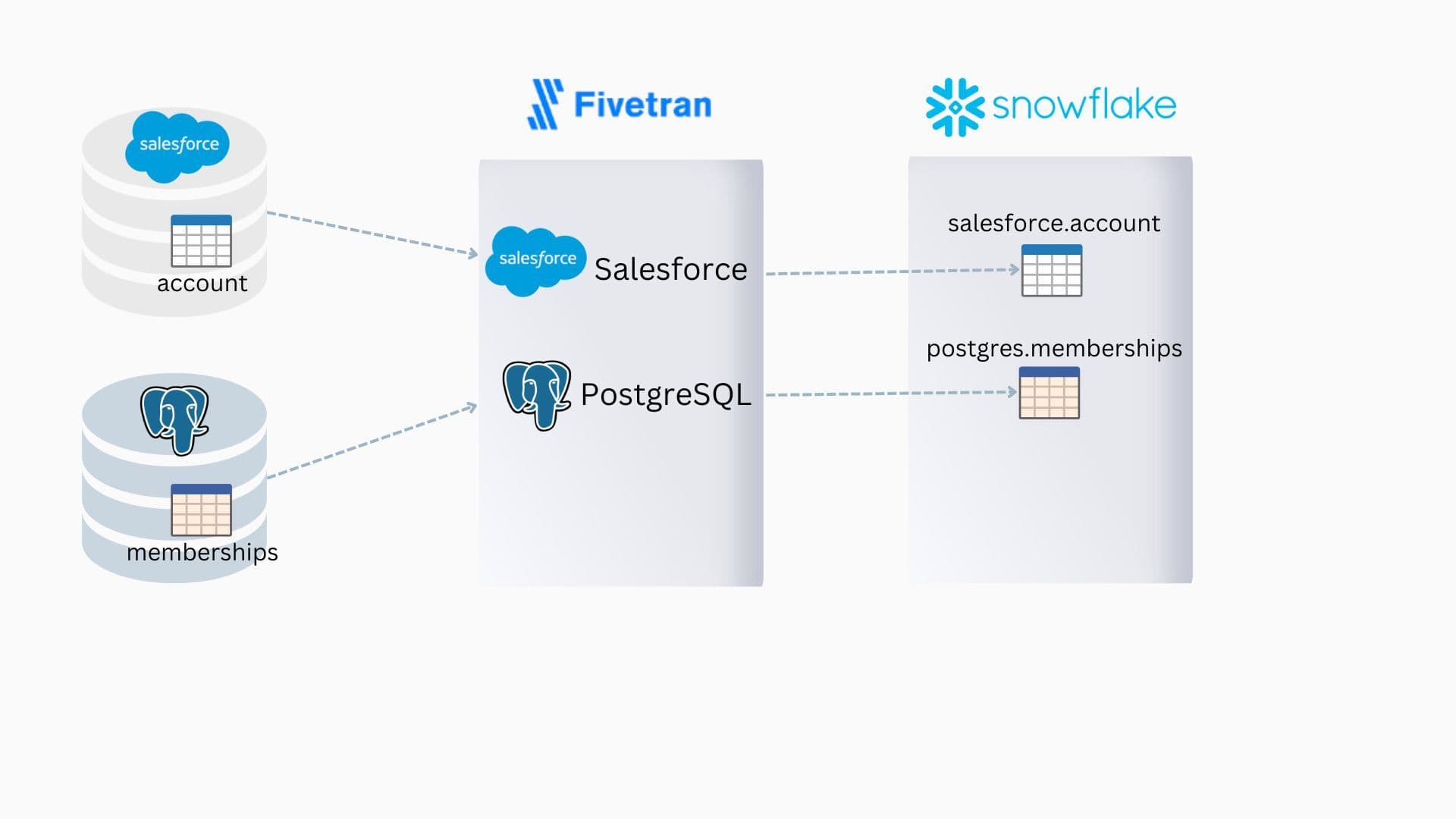
Using Fivetran for ELT jobs into Snowflake
Then we jumped into Fivetran to configure connectors for both Salesforce and Postgres and set the desired frequency of Fivetran ELT updates (keeping in mind that each time the Fivetran sync runs, our entire data activation pipeline would be triggered).
In this proof of concept, we set the frequency for both connectors to 15 minutes.
Step Two: Create the dbt Model
Next, we used the Fivetran transformation function to build a dbt model that joins our two data sources and calculates the active user count.
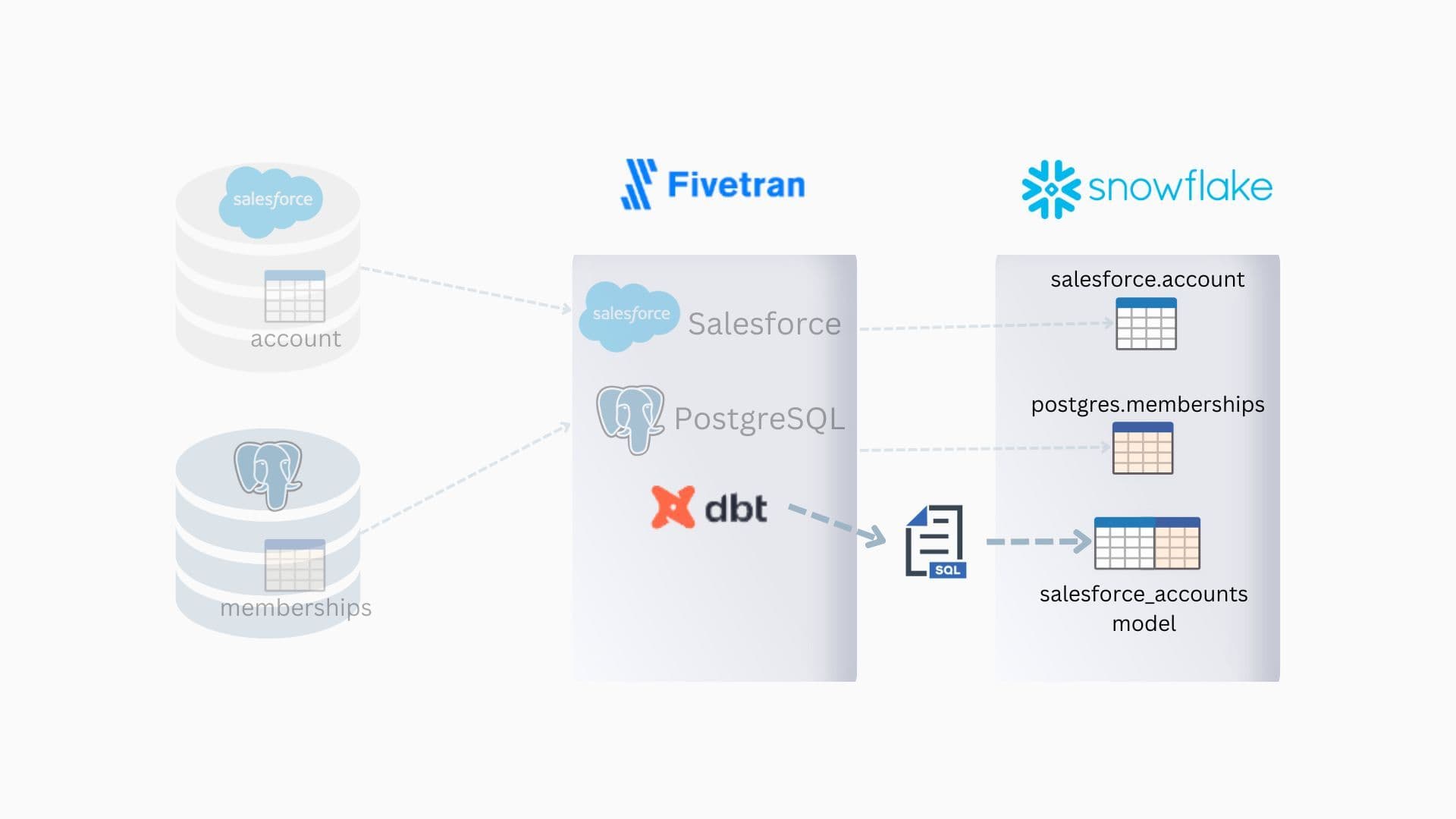
Building a dbt model
We created a new dbt model (code below) to perform the calculation and committed it to our dbt project in GitHub.
with
web_groups as (
select * from {{ ref('stg_website__groups' ) }}
),
web_memberships as (
select * from {{ ref('stg_website__memberships' ) }}
),
web_users as (
select * from {{ ref('stg_website__users' ) }}
)
select
web_groups.domain,
count(*) as active_user_count
from web_memberships
join web_groups using(group_id)
join web_users using (users_id)
group by 1
Step Three: Configure the dbt Transformation in Fivetran
Next, we added a new Fivetran transformation and selected this specific dbt model. The screenshot below shows the “fully integrated” option. Now, after the upstream connectors finish running a sync (Salesforce and Postgres, in this example), Fivetran will build our new dbt model.
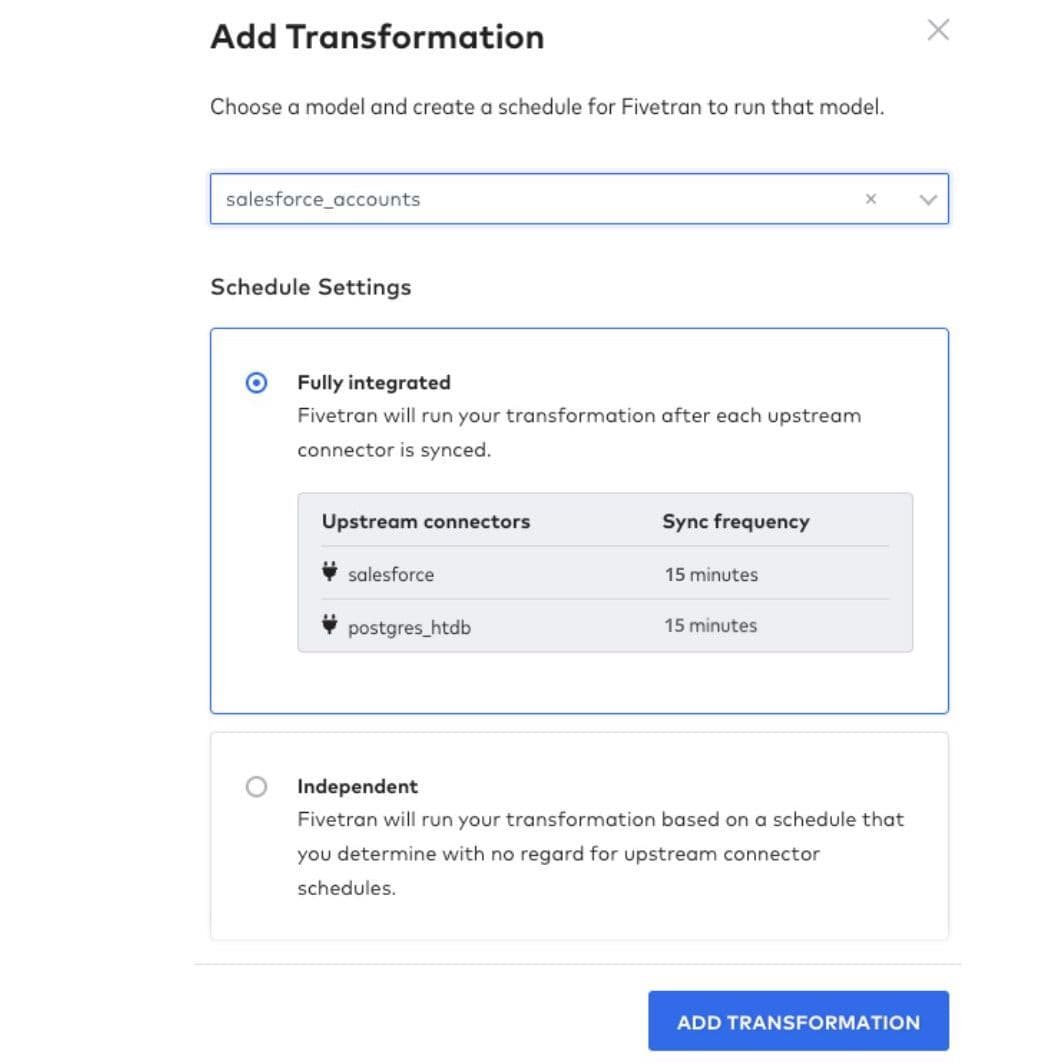
Configuring the dbt transformation
Step Four: Configure the syncs to Salesforce in Hightouch
The last step of this pipeline is to create a Hightouch sync that moves data from our new dbt model (in Snowflake) into Salesforce production.
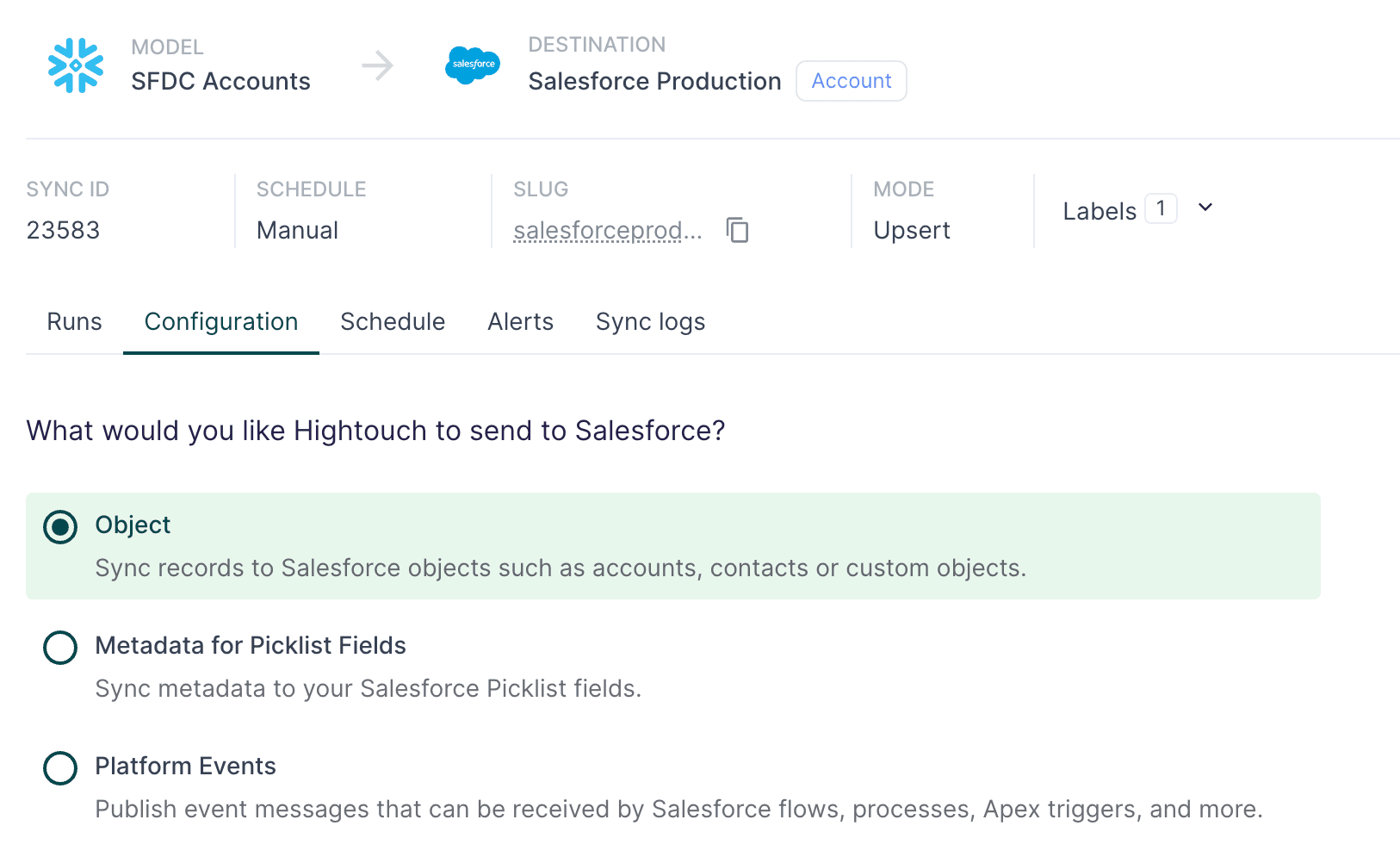
Sync configuration in Hightouch
Since our source and destination were already set up in Hightouch, this was a straightforward process and just required a few configuration instructions from me. This playbook offers more details about how to set up a sync from any source into Salesforce.
Step Five: Use the Hightouch Fivetran integration to Schedule the Sync after the dbt Model in Fivetran Completes
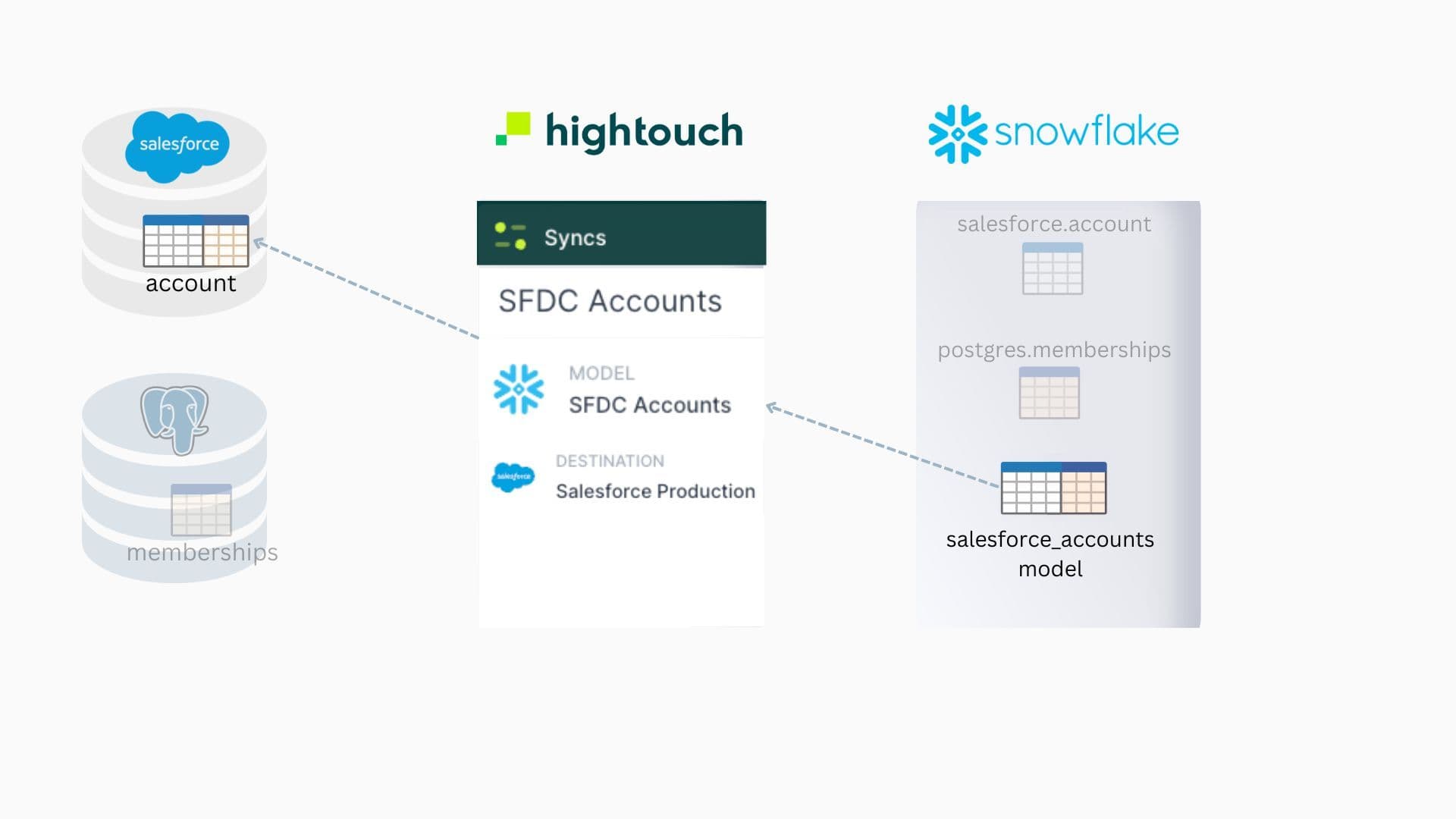
Automatically initiate Hightouch sync once Snowflake is updated
The final step is to configure the Hightouch sync to run immediately after the Fivetran job completes by selecting the new Fivetran extension in the schedule type. The way it works is Fivetran will send a message to Hightouch each time the dbt model builds and Hightouch will automatically then perform the sync to move the transformed data into Salesforce.
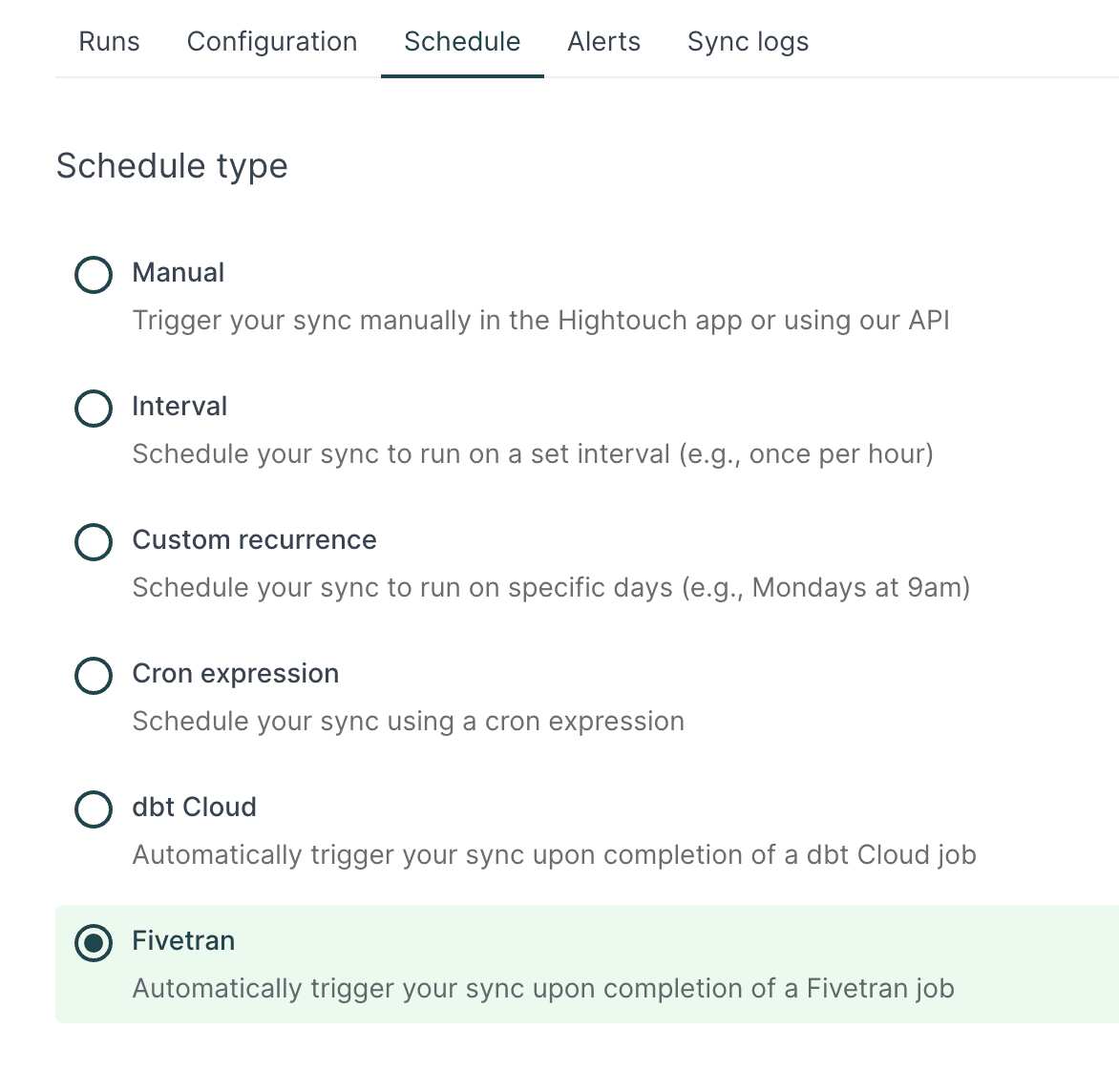
Scheduling the Hightouch sync to run once the upstream Fivetran jobs completes
Voila! In less than 15 minutes, our data team automated a new end-to-end data pipeline that ensures that our customer success teams have the freshest possible data flowing so they can best support our customers. All just using each tool’s existing scheduling functionality…and not needing to rely on a third-party orchestrator 🙌.
Conclusion
After evaluating the new extension, our team learned how easy and fast it is to use Hightouch and Fivetran to sync transformed data and provide near real-time metrics to SaaS tools like Salesforce. They were particularly excited about being able to leverage Fivetran’s sync dependencies capabilities (lineage) to optimize their activation workflows by ensuring that dbt transformations (and downstream Hightouch syncs) only ran once all ELT pipelines were complete.
Specifically, they cited two exciting new outcomes for data teams:
- Early-stage data teams can move faster without needing to rely on a third-party orchestrator to move that data through their pipeline.
- Established data teams—who maybe already use an orchestrator—can easily add (near) real-time components to their workflows without changing batch jobs (or needing to understand the complexities of the overall data pipelines to do so).
It’s no secret that orchestration is often complicated to manage. Luckily the modern data stack continues to evolve to build native scheduling and messaging functions and better support cross-tool interoperability. This gives data teams precious time back to work on more high-value engineering tasks while trusting that the data is getting piped exactly where it belongs, when it belongs there.
The Hightouch Fivetran extension is available today. Check out the Docs to learn more.










