Data downtime destroys value
As you unlock more value from data, downtime becomes more costly. A Monte Carlo survey reveals data downtime has increased nearly twofold year over year.
Michael Segner
May 2, 2023
|5 minutes

It’s ironic in the two thousand spoons sense of the word. The more effort a data team puts into unlocking value from their data, the more visible and severe an instance of data downtime becomes.
No executives care about data quality when the data is sitting idle and gathering dust in the data warehouse, but it becomes a frequent question once it starts adding value to the business. Few technologies add more business value than the Customer Data Platform, which is why it is so important to:
- Extract the value: Break down the data silo created by legacy CDPs so data can be fully activated from the warehouse and composable CDP.
- Preserve the value: Implement data observability end-to-end across production data pipelines.
This first point was covered in the death of legacy CDPs, so in this post, we’ll quantify the risk data downtime poses to this value creation with help from the results of the survey we released earlier this week.
Your Customer Data Is Important, Treat It That Way
The increasing value of activated data parallels the experience of the earlier days of software engineering and the internet when sites like Google and Amazon realized minutes of downtime translated into millions of dollars lost.
It’s not ideal when a dashboard surfaces stale data, but in many cases, it’s not exactly a crisis. But what if that same data freshness problem occurs across a data pipeline that is plugged directly into a marketing automation program? The result is stale audience segments, increasing customer acquisition costs, and a frustrated marketing team.
SaaS API integrations are fragile things. At one of my former employers, I discovered a month’s worth of leads had not transferred from LinkedIn to Marketo to our CRM system. Turns out the API authorization from LinkedIn to Marketo had expired with no notice.
This significantly diluted the value of about $30,000 worth of leads (speed to lead is real!), impacted go-to-market operations, and consumed hours of the marketing team’s time to troubleshoot and resolve the issue.
Based on this experience, it doesn’t surprise me to see that respondents to our survey reported poor data quality impacted 31% of revenue on average. Nor that it was a five percent increase year over year.
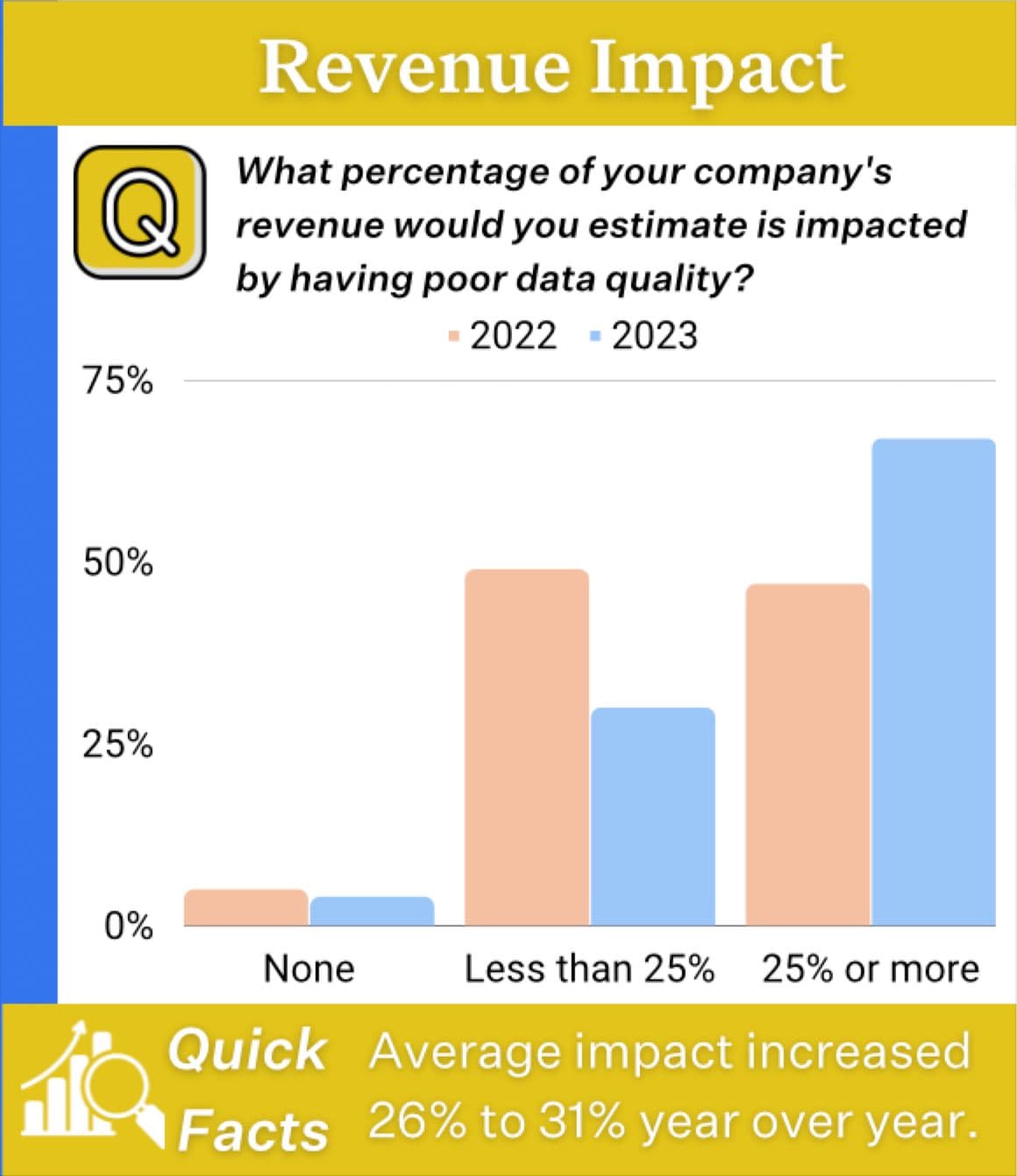
Imagine if this data workflow had instead involved robust, monitored data pipelines that sent alerts when the lead count for LinkedIn had become anomalously low.
Being First To Know
Who catches the incident matters as well. If the data engineer spots a batch job filled with garbage NULLs, they are a hero. When it’s caught by your internal data consumers, it's embarrassing. But what happens when it becomes part of a customer-facing personalization application?
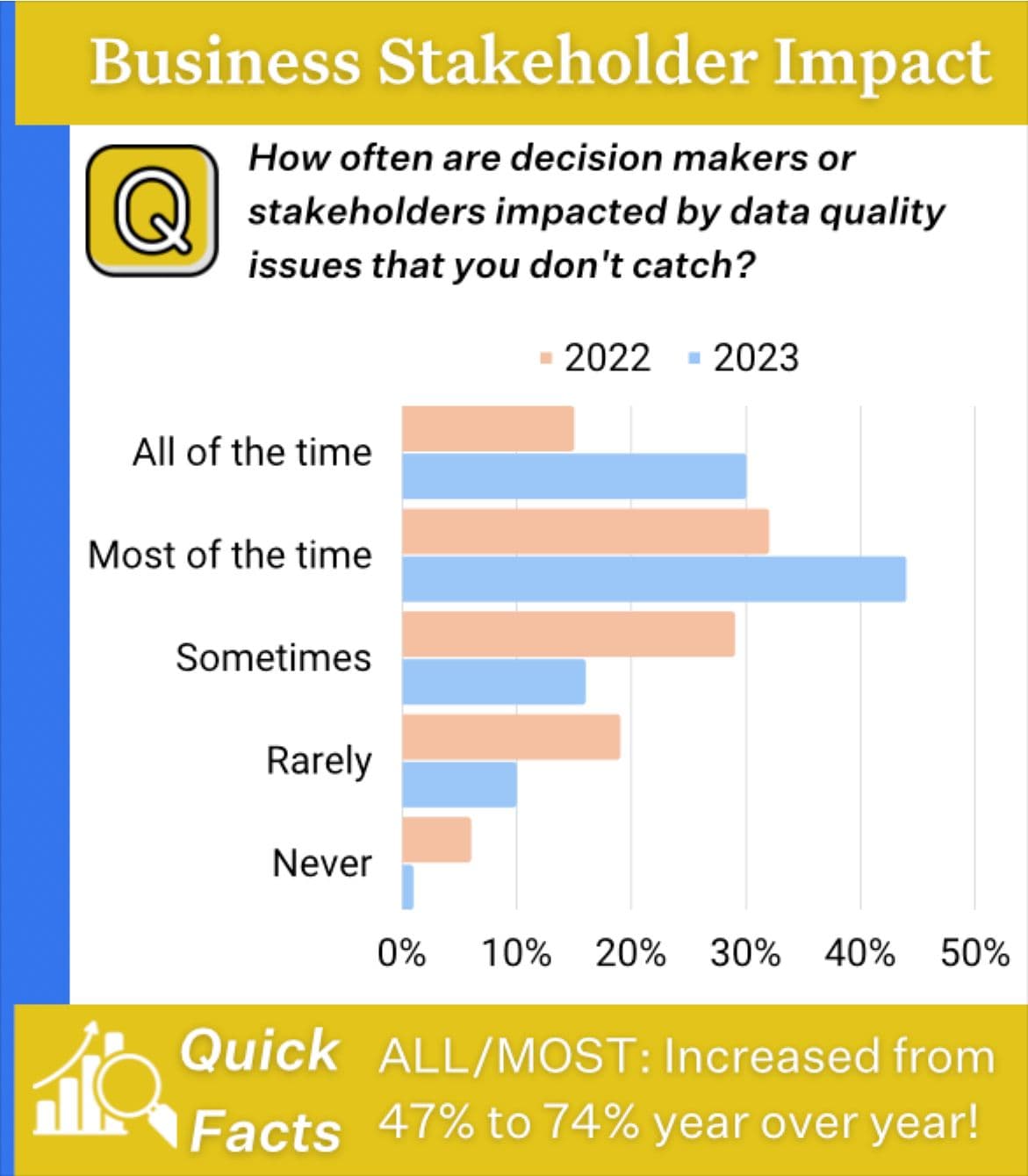
In our survey, 74% of respondents said decision makers or stakeholders were impacted by data quality issues they didn’t catch “all or most of the time.”
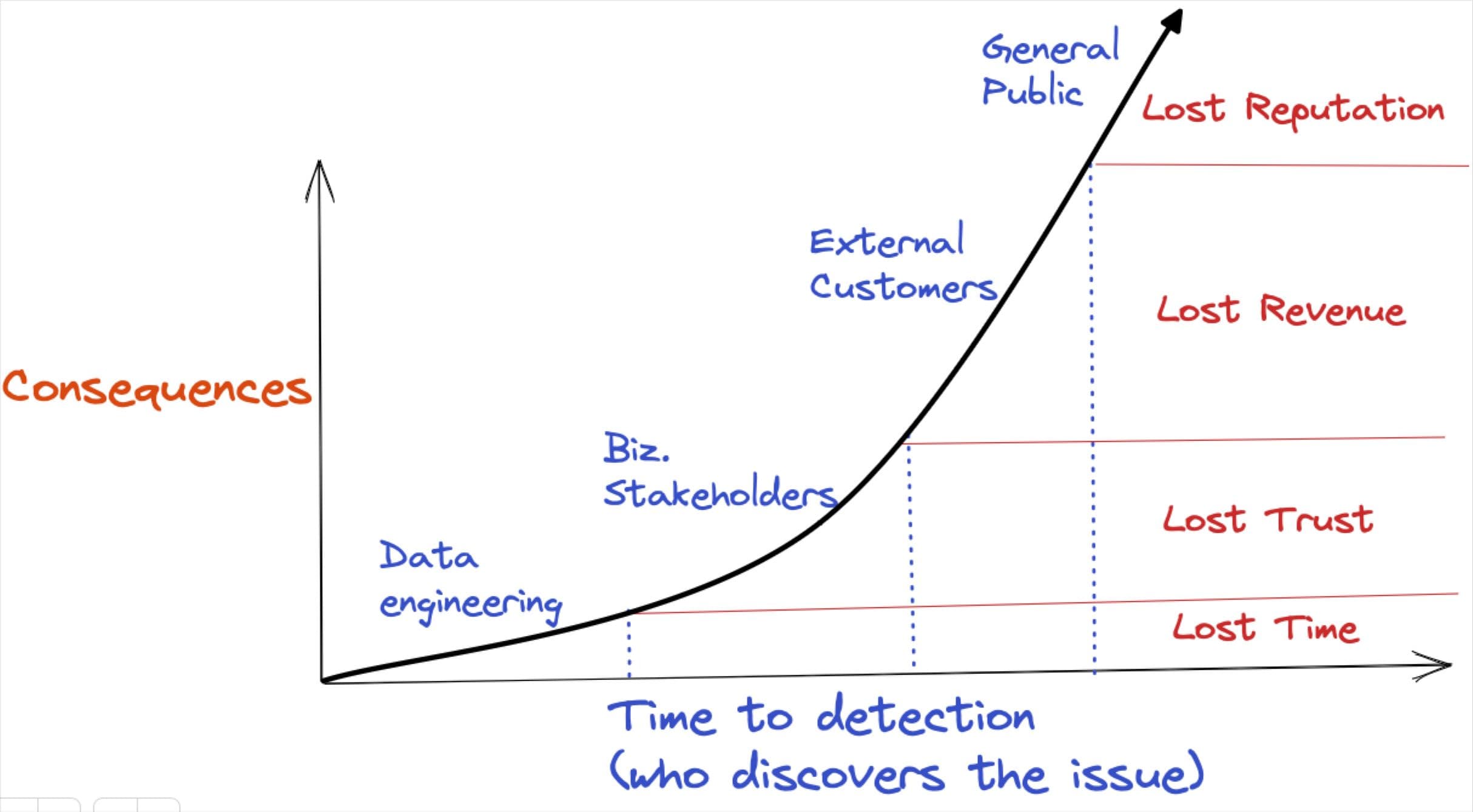
Today’s go-to-market operations are too sophisticated for legacy CDPs, and they are too important not to have data observability as part of the modern data stack and composable CDP.
Friends Don’t Let Friends… Exclusively Unit Test For Data Quality
There are generally three reasons to implement a technology: lower costs, increase ROI, and reduce risk. A composable CDP offers all three benefits by eliminating storage redundancy, adding richer insights natively within the warehouse, and providing better monitoring through data observability.

Be right back, I gotta go buy a web domain. Annotations courtesy of Monte Carlo.
Just like traditional customer data platforms, data testing is a legacy approach to data quality. While it does still have a supporting role to play on your most important pipelines and within data contracts, data testing alone is not a solution to data quality.
No human is able to write a test for all the different ways data can break. Doing so would be incredibly time intensive and frankly wasteful–and trying to scale this across each dataset would be a nightmare. Data observability platforms like Monte Carlo leverage machine learning to more efficiently monitor and detect issues like:
- Data freshness: Are your tables updating at the right time?
- Data volume: Do your tables have too many or too few rows?
- Data schema: Did the organization of the data change in a way that will break downstream systems?
- Data quality: How is the quality of the data itself? Are the values in an expected distribution range? Are there too many NULLs? Too few unique values?
As important as quick time-to-detection is, it’s only half the story. Our survey found data downtime nearly doubled year over year, driven primarily by a 166% increase in time-to-resolution.
As your stack grows in complexity, it can become more difficult to efficiently resolve each incident. That’s because incidents can occur at:
- The system level: An airflow job failed
- The code level: A bad LEFT JOIN
- The data level: A CSV filled with NULLs
Data observability provides capabilities to accelerate resolution at each level such as data lineage, query change detection, dbt/Airflow integrations, and high correlation insights. With this coverage from ingestion to visualization (and to activation with Hightouch’s alerting and monitoring capabilities), data teams can feel confident pushing the limits of their data flows.
Now the limits to the value you unlock won’t be data downtime, but your imagination.
Interested in learning more about data observability? Request a demo today.










